At the time of writing Github Actions has a free tier allowing 2,000 minutes a month of builds for private repos. For smaller / side projects that are already hosted on GitHub it is straightforward to setup a PR based workflow to automate the deployment process.
A CI/CD process suitable for a small project could be:
- PR workflow:
- on every pull request commit targeting main branch:
- run all tests
- run
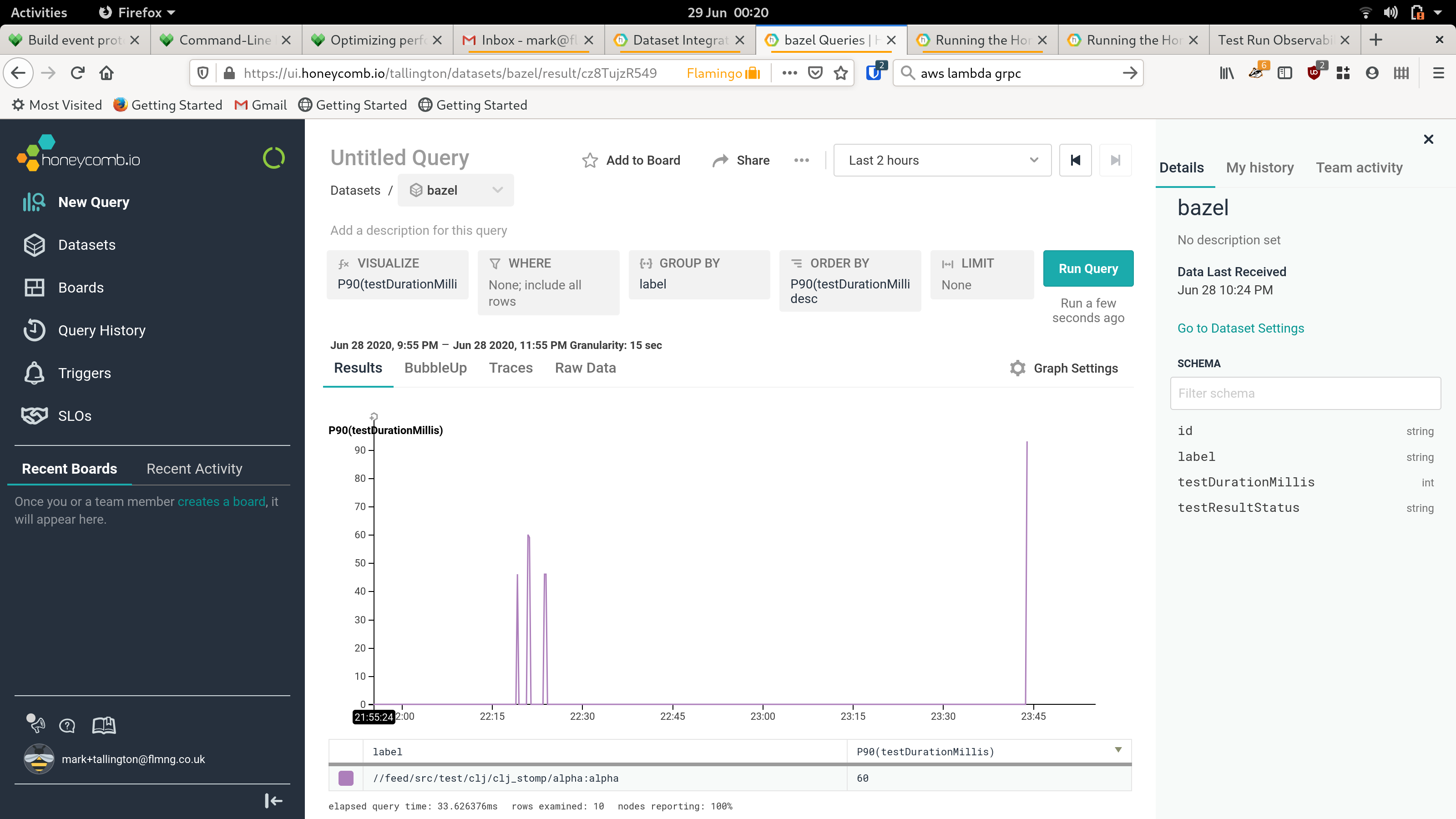
cdk synthand to produce a Cloud Assembly directory (cdk.out) with the latest changes - run
cdk diffwith the produced Cloud Assembly - post diff as a comment to the PR
- on every pull request commit targeting main branch:
- Main workflow:
- on every commit to main branch:
- acquire cdk.out artifact from the PR workflow synth
- run
cdk applywith that Cloud Assembly
- on every commit to main branch:
Currently Github actions don’t make it too easy to share artifacts between different workflows (see https://github.com/actions/download-artifact/issues/3). It is now possible via wrangling the APIs but until it gets polished we’ll amend the main workflow as follows:
- Main workflow:
- on every commit to main branch:
- run
cdk synthand to produce a Cloud Assembly directory (cdk.out) with the latest changes - run
cdk applywith the produced Cloud Assembly
- run
- on every commit to main branch:
PR Workflow
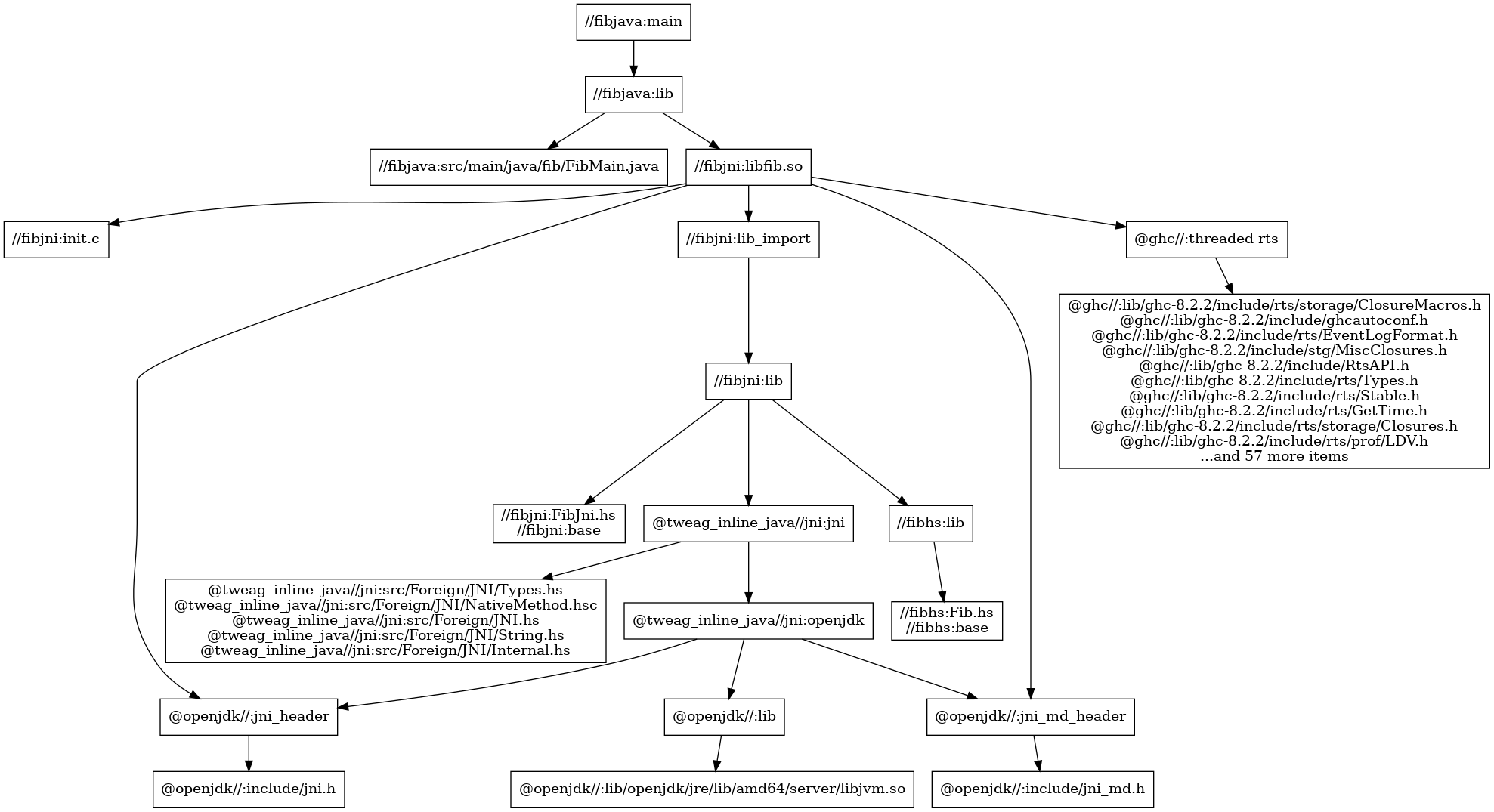
Using the same repo as previously introduced https://github.com/markdingram/bazel-cdk-clojure, a pr.yml workflow is added.
Aside: I lost count of the number of broken links I saw from not using permanent Github links - to get a permalink simply press
y
While the generation of the cdk.out directory uses Bazel, the diff / apply of that product is done without reference to Bazel using an NPM installed CDK binary. Simplifying down this example for a pure NPM Javascript project would be straightforward.
The workflow shouldn’t be complicated to follow, in the build job the steps of interest are:
- name: Test
run: |
bazel test //...
- name: Synth
run: |
bazel build infra:synth
find dist/bin/infra/cdk.out -type d -exec chmod 0755 {} \;
- name: Upload Cloud Assembly
uses: actions/upload-artifact@v1
with:
name: cdk.out
path: dist/bin/infra/cdk.out
As required run all tests first. A Bazel synth rule has been added to output the Cloud Assembly dist/bin/infra/cdk.out via bazel build infra:synth.
As of now CDK likes to add ‘.cache’ directories inside the cdk.out directory when uploading assets to S3. Given all Bazel output is read only make the directories writable prior to uploading as an artifact.
In the diff job the steps of note are:
- name: Download Cloud Assembly
uses: actions/download-artifact@v1
with:
name: cdk.out
- name: Run CDK diff
run: node_modules/.bin/cdk diff -c aws-cdk:enableDiffNoFail=true --no-color --app cdk.out "*" 2>&1 | tee cdk.log
- name: Add comment to PR
env:
URL: $
GITHUB_TOKEN: $
run: |
jq --raw-input --slurp '{body: .}' cdk.log > cdk.json
curl \
-H "Content-Type: application/json" \
-H "Authorization: token $GITHUB_TOKEN" \
-d @cdk.json \
-X POST \
$URL
JQ is used to slurp the raw text output of CDK diff into a JSON message suitable for uploading to Github. Presumably there is a Github action that would encapsulate the PR comment posting, but the Rest API is so straightforward adding a dependency for that seems overkill.
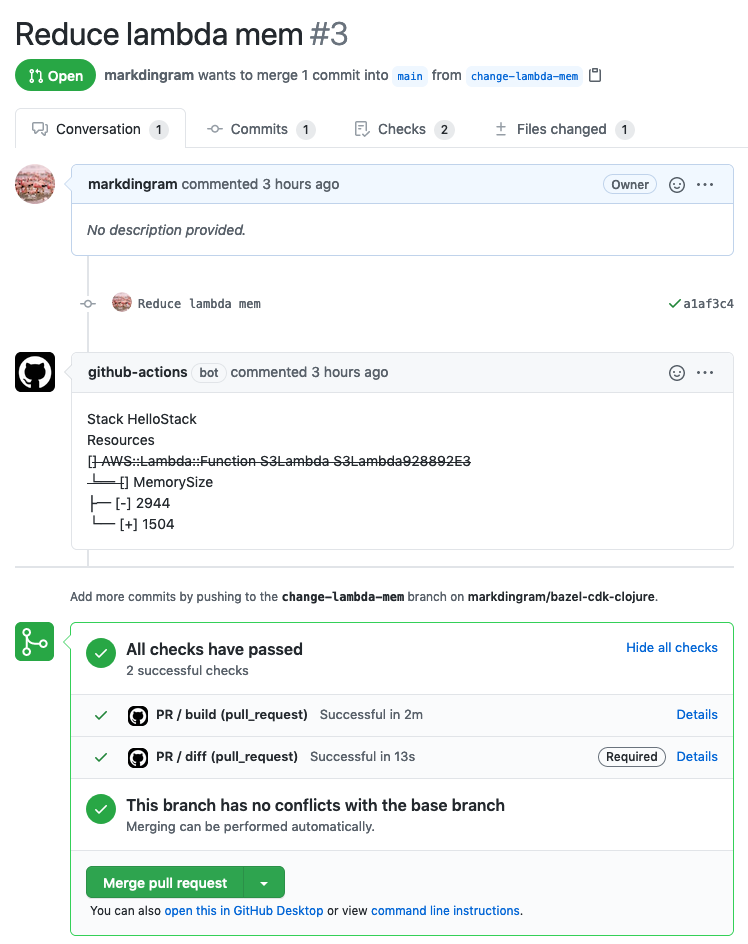
With this workflow in place a CDK diff should spring onto the PR after a few minutes:
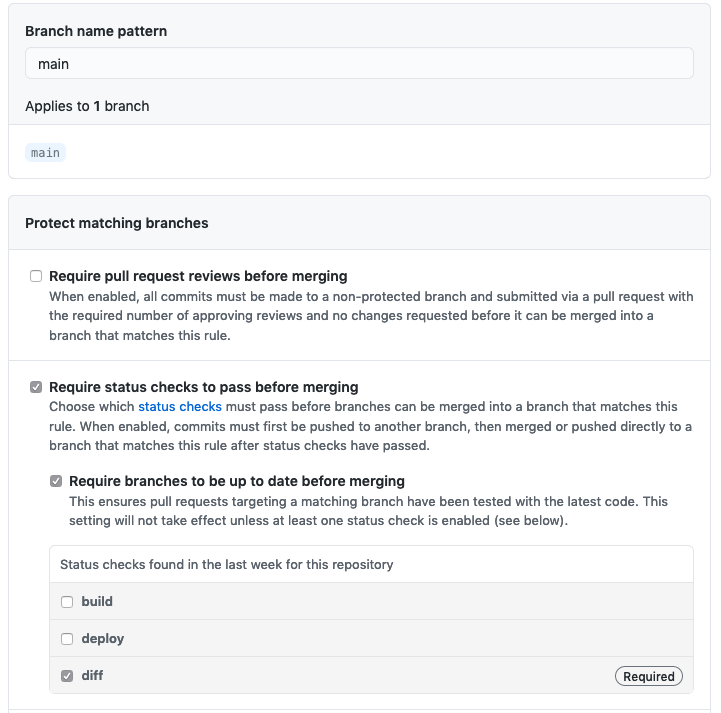
It is also useful to setup a Github Branch protection rule that ensures the PR workflow is successful prior to merge:
The main workflow is similar to the PR one, but with a cdk deploy step instead.
Notes
-
I first encountered showing planned changes on Pull Requests from Atlantis a couple of years ago. I believe Hashicorp hired the maintainer from that to work on Terraform cloud, so worth checking both of these for inspiration!
-
The Amazon equivalent AWS CodeBuild free tier is only a miserly 100 minutes. After the free tiers run out the AWS lowest tier of build instances (general1.small) is cheaper than GitHub ($0.005/minute for a general1.small vs $0.008), but has less RAM (3GB compared to 7GB). For larger projects I’d be inclined to pursue AWS (configured via CDK of course!). The CodeBuild / CodePipeline constructs & further integration over time with CDK / CloudFormation will likely allow more detailed/involved workflows to be constructed.